
The heart of the semantic integration problem is how to tell when two statements are about the same subject. In some circles, this is known as the “co-referencing problem”. It is problem familiar to those who sift and scrub intelligence gathered from diverse sources, and it is known to be hard. One of the reasons that it’s hard is that some statements define (or contribute to the definition of) the subjects they’re talking about.
Keywords: Topic Maps; Semantics
| XML Source | PDF (for print) | Author Package | Typeset PDF |
This document is a set of annotated slides that was used by the author at Extreme Markup Languages 2003 to propose a definition of semantic integration and a Methodology for achieving it. The Methodology accommodates diverse worldviews, and it compromises neither the independence of knowledge contributors, nor the integrity of their contributions.

The heart of the semantic integration problem is how to tell when two statements are about the same subject. In some circles, this is known as the co-referencing problem. It is a problem familiar to those who sift and scrub intelligence gathered from diverse sources, and it is known to be hard. One of the reasons that it’s hard is that some statements define (or contribute to the definition of) the subjects they’re talking about.
It is reasonable to assume that the publicly-available information on the Semantic Web will be intended to be semantically integrated by anyone with any other information. Semantic integration on the Semantic Web, then, could conceivably present a more tractable co-referencing problem than the one faced by the intelligence community, which gathers much information that was not intentionally contributed, and which was usually not created with the intent that it be semantically integrated with other information.
What form would be ideal for supplying arbitrary information to broad aggregations of knowledge, such as the Semantic Web, assuming that the supplier intends it to be most readily amenable to semantic integration with other information? How can such aggregations of knowledge be completely open with respect to semantics, including ontological semantics, and at the same time facilitate semantic integration in a meaningful way?
In these slides, I’m representing ideas — concepts, subjects of conversation — as lightbulbs. The lightbulbs represent “pure” subjects, quite apart from any symbols or other representations of them.
When we humans communicate with each other, we have to assume not only that we have some symbols (words, etc.) in common, but also that we share some common ideas. We necessarily assume that, at least some of the time, humans communicate so successfully and compellingly that they really do grasp the same idea. Normally, we also necessarily assume that the fact that two conscious entities are aware of an idea, or that they are talking about an idea, does not cause there to be two ideas. We also assume that all ideas are unique — that, in some sense, ideas have identity.

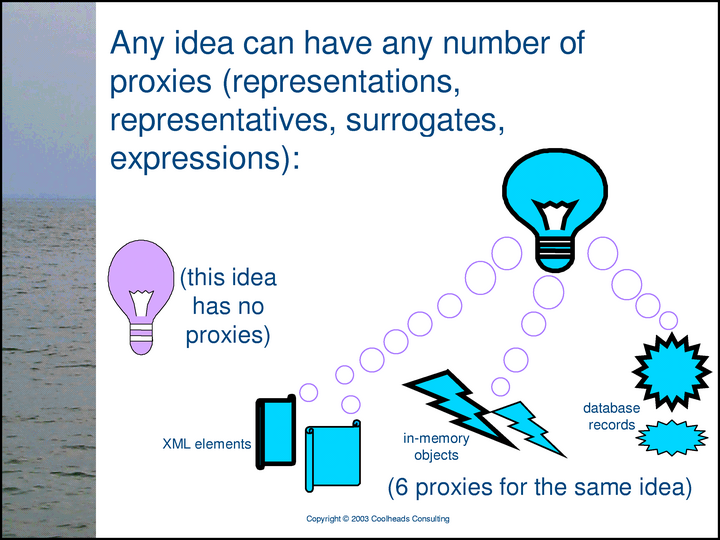
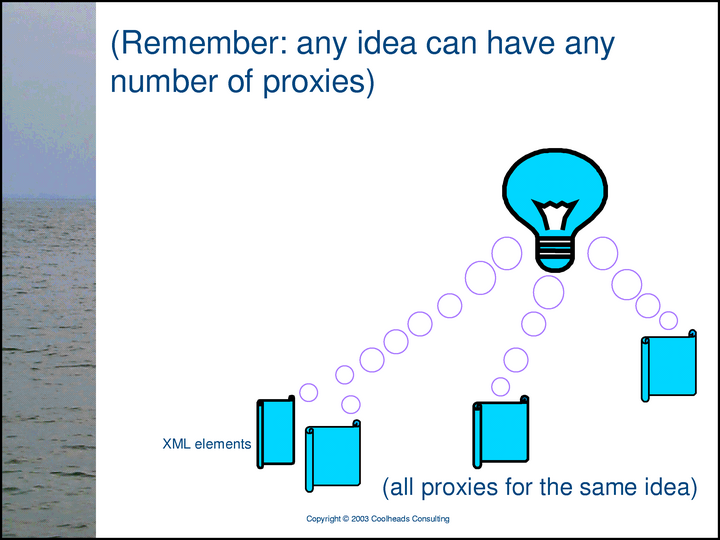
However, any idea can have any number of expressions; it can be the subject of any number of statements, in any number of conversations.
When we decide to manage information according to the ideas to which it is relevant, we can create indexes, such as the indexes often found in the backmatter of printed books. Each entry in an index is a proxy for a single subject of conversation, and the pages in the book that are considered relevant to that subject are, in some sense, properties of that proxy.
More generally, there are many occasions in which a specific unit of information serves as a kind of surrogate for a subject of conversation. In Topic Maps, for example, XML elements called <topic>s serve as proxies for subjects.
Subject proxies are not always pieces of text. For example, when a Topic Map tool has read an XML topic map document, it typically has a set of in-memory objects, each of which serves as a surrogate for a specific subject. For another example, it is often useful to regard certain kinds of records in relational databases as proxies for specific subjects.
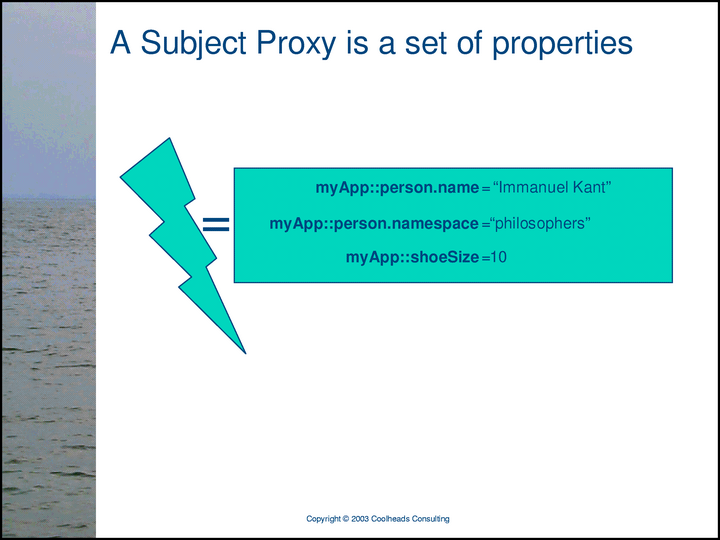
In this presentation, I’m using a visual vocabulary that provides three kinds of subject proxies: scrolls are XML elements used as subject proxies, lightning bolts are in-memory objects used as subject proxies, and 16-pointed stars are relational database records used as subject proxies. (There are many other kinds of subject proxies, of course.) N.B.: Lightbulbs are not subject proxies; they are the subjects themselves.
All human communication can be seen as expressions of relationships between subjects of conversation. Any piece of information, when understood, can be understood as a network consisting of subjects and the relationships between those subjects. If there are multiple interpretations of a given piece of information, each such interpretation is such a network.
This slide depicts the world of ideas/subjects (lightbulbs). In this world are found the meanings of human expressions, rather than the expressions themselves. Or there may not be any expression whatsoever that corresponds to this constellation of ideas (this Network of Subjects and Relationships). This network may, for example, be someone’s unconscious, unexpressed worldview. Or it may represent some combination of views that have been conceived separately, but that nobody has ever actually combined. (The potentially enormous value to society of facilitating such combinations, and making them useful and visible, is the primary motivation for the development of the Semantic Integration Methodology described in this presentation.)

The network of subjects and relationships shown in the previous slide is useless, because it is not being communicated or represented in the real world. In this slide, the same network of subjects and relationships has been made real by endowing each subject with a proxy. (In this particular slide, the proxies are all in-memory objects — lightning bolts.) Thus, the network of subjects and relationships is tangible, processable, and useful.
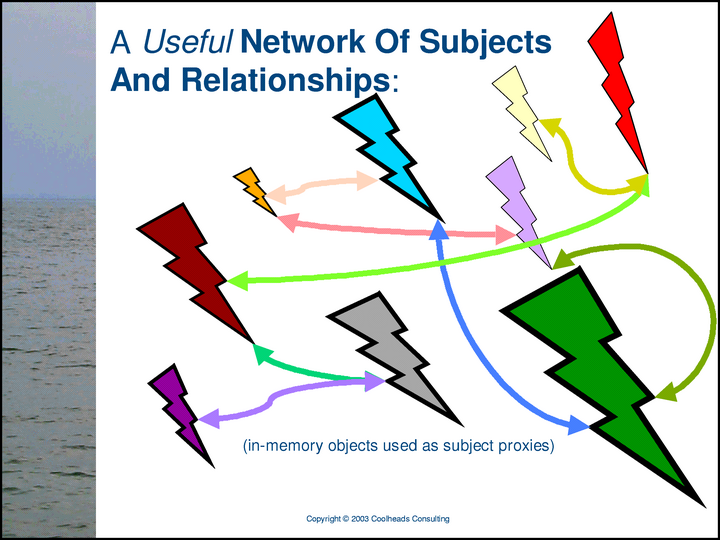
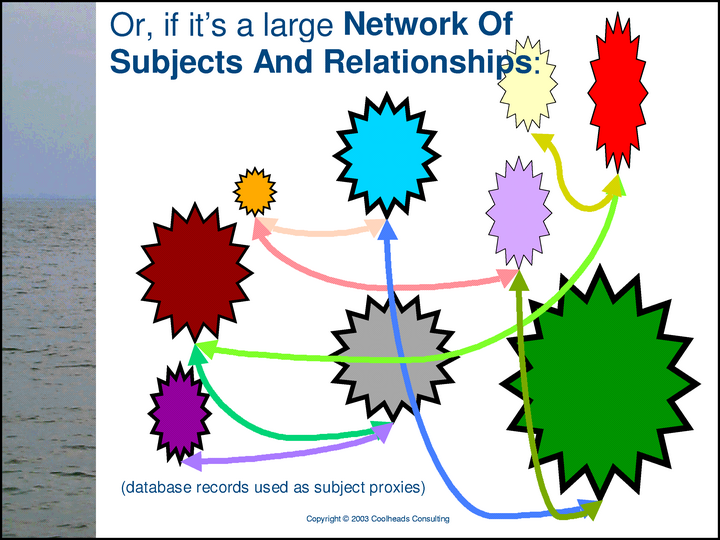
Computer memory is always a limited resource, but there the quantity of knowledge that can be usefully represented in a network of subjects and relationships is unbounded. In this slide, we’re using a relational database to increase our scale — to allow us to manage more subjects (more subject proxies) than we could handle using only in-memory objects.
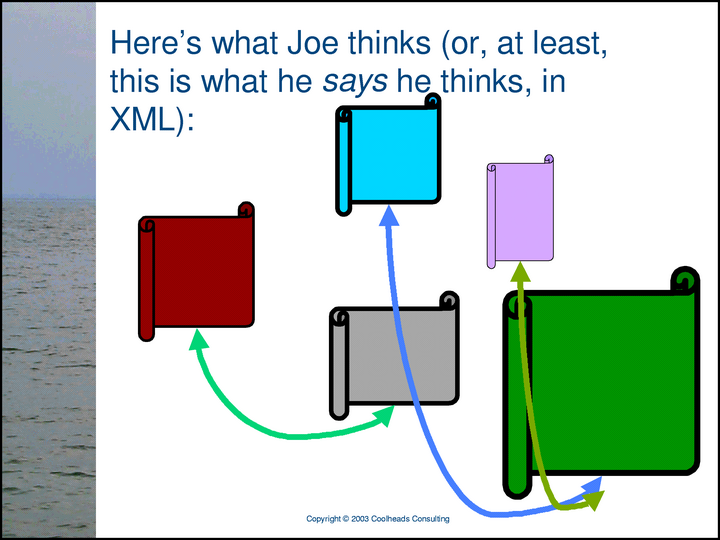
We can represent a network of subjects and relationships in XML, too, usually for the purpose of information interchange. Perhaps all the proxies in this slide are elements in a single XML document, or perhaps they are distributed across several XML documents.

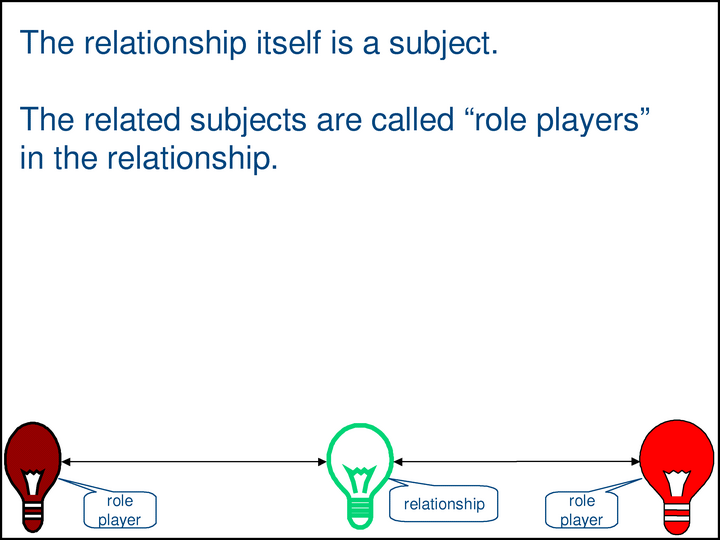
It’s important to understand that there is no network of subjects unless the subjects have relationships to one another.
Without relationships, nothing is being said. All statements are statements of relationships among subjects.

People can publish their views in the form of XML documents that represent networks of subjects and relationships. Here is Joe’s XML document.
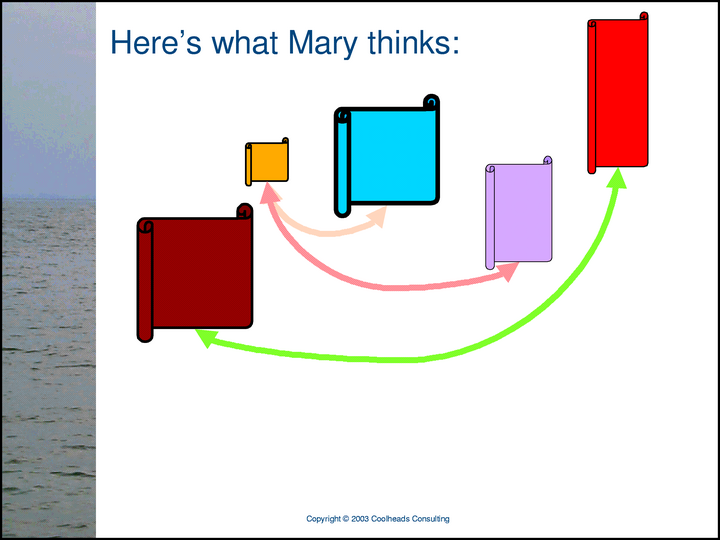
Here’s Mary’s XML network of subjects and relationships.
Here’s the World Almanac’s XML network of subjects and relationships.
Joe and Mary say different things three of the same subjects. Wouldn’t it be great if, when we needed to know something about one of those subjects, we could know what both Joe and Mary thought?

Joe and the World Almanac have different things to say about two subjects.

In addition to the different things they have to say, Mary and the World Almanac make exactly the same statement, here depicted as a pair of light-green double-headed arrows. Each arrow has a proxy for the brown subject as one role-player in the relationship, and a proxy for the red subject as the other role-player.
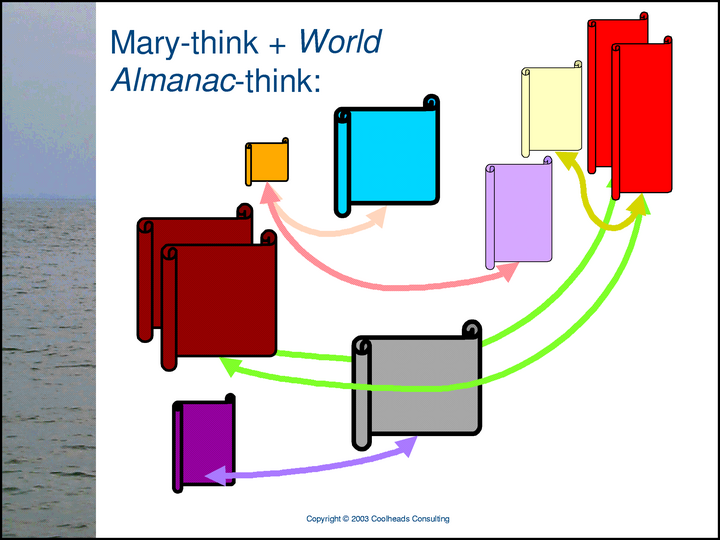

Let’s imagine that we have software — a Methodology engine — that can read Joe’s, Mary’s, and the World Almanac’s XML representations of their respective Networks of Subjects and Relationships, and translate them into corresponding sets of in-memory objects. Despite the fact that the result includes multiple in-memory proxies for some subjects...

… the combined network really ought to be the network of subjects and relationships depicted in this slide, because …
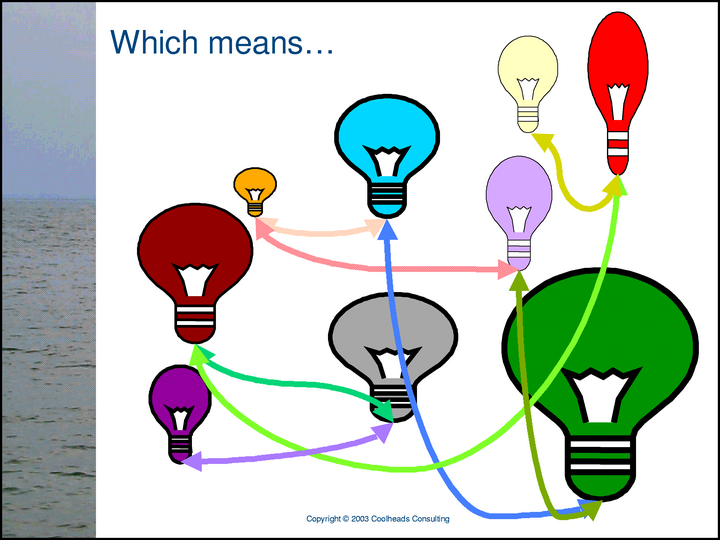
… any subject can have any number of proxies, but it is still a single, unique subject.
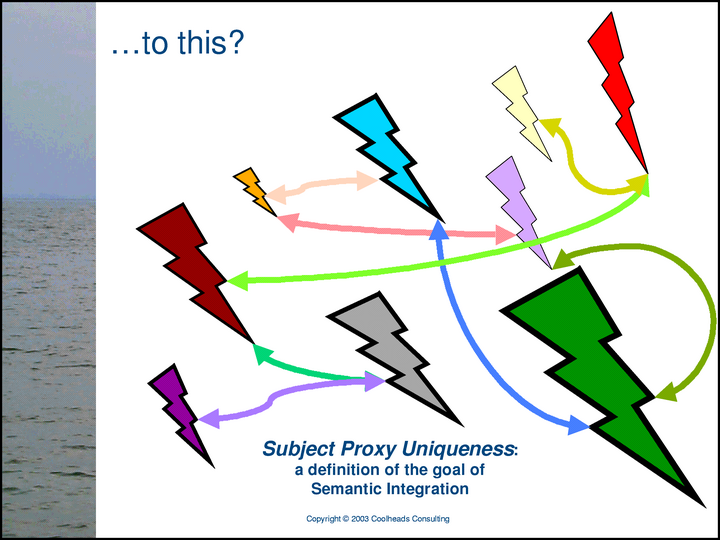
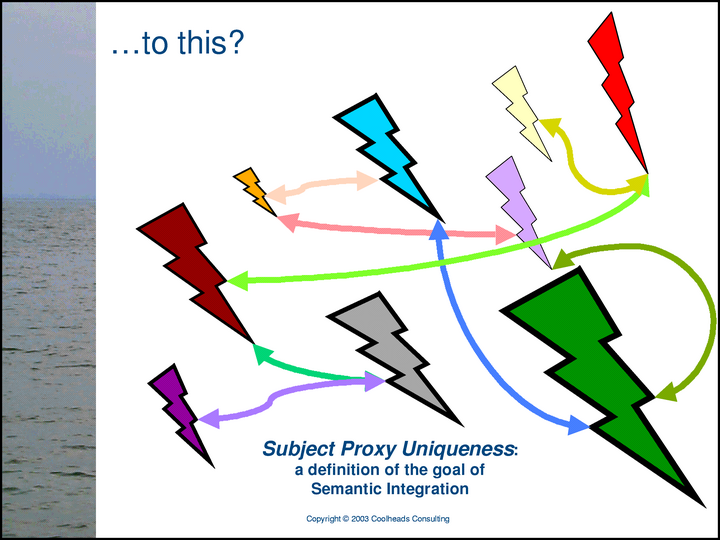
The problem that the Methodology addresses is the problem of combining multiple, independently-conceived representations of Networks of Subjects and Relationships, with their separate, partially redundant proxies for the same subjects, in such a way that …

… for each subject, there is only one proxy, but no information has been lost. The Methodology’s definition of semantic integration is subject proxy uniqueness.
The Methodology answers the questions:

The Methodology is expressed as a potential ISO standard, as the Draft Reference Model for Topic Maps (http://www.isotopicmaps.org/rm4tm). The future of the Methodology is unknown.



The word “Applications” has special meaning here, which is why it appears in doublequotes. “Applications” of the Methodology are not implementations of it; they are more like languages, with built-in notions about how one may determine whether two proxies are, in fact, proxies for the same subject.


We’ll discuss each of the features of the Methodology in turn, beginning with the answer to the question, “What is a subject proxy, really?”









Establishing authorities for the names of subjects is something that many (and, arguably, most) people do, and that’s the problem. At the scale of the Semantic Web, the idea that a few subject naming authorities will give names to everything we need to talk about will not work very well as the basis of semantic integration. There are many reasons why it won’t work. One of them is that, as some wag once noted, the greatest thing about standards is that there are so many to choose from. But the basic problem is not that there are so many “standard” vocabularies, etc.; the basic problem is human nature, and in the nature of human communication. It can be argued that it is impossible to write pointed prose without either using existing terms idiosyncratically, or inventing new terms. This may be the true nature of the Curse of Babel — that human communication necessarily invents itself, to at least some degree, whenever it occurs. Again: a statement can be about a subject, and it may also define (or contribute to the definition of) the thing it’s talking about.
So, if common terminology — common names for subjects — is not a scalable basis on which the Semantic Web can merge proxies for identical subjects, on what basis can it be done?
Well, it can be done on the basis of a common ontology, if the common ontology provides a logical basis on which statements about subjects can identify them, for all purposes of deciding whether any two subject proxies are proxies for the same or different subjects. Even an ontology with very few, very simple types of assertions can provide such a basis, if they are all widely understood and honored. (Indeed, this is the approach used in the SAM [Standard Application Model] of Topic Maps, in which subjects can be asserted to have “subject indicators”. The “subject indicator” approach is more practical than attempting to get everyone to use the same subject identifiers. The subject indicators — arbitrary pieces of subject-describing information — are, in effect, the subject identifiers, but they have the added virtue of actually describing the subject in some compelling way. Subject indicators at least provide a more compelling basis for recognizing subject identity than, say, most URLs would normally be. Furthermore, the *context* of a subject indicator — the location in which it appears — can make it far more compelling and authoritative, and far more descriptive of its subject, than any context-independent name could possibly be.)
Unfortunately, the development of a single, universal ontology for subject identification — an ontology that everyone in the world will use to identify all subjects, forever — is a quixotic endeavor. We in the SGML/XML world know this in our very bones, because it is so similar to such ill-starred, scopeless ideas as the One True “ODA [Office Document Architecture]”. Any attempt to realize such an idea will probably absorb whatever resources are allocated to it, but without yielding the intended result.
No, in order to achieve the goal of Web-scale semantic integration without compromising the semantic authority of each information contributor, we have to take another step back. We have to content ourselves with saying how ontologies for subject identification and discrimination must be defined, and to provide a basis for diverse ontology definitions such that the semantic integration of diverse information expressed in terms of those ontologies is facilitated. The Methodology provides these things.

The next feature we’ll discuss is the Methodology’s answer to the question, “What’s a relationship?”


Note that we have two statements (here depicted as the two green double-headed arrows) that say the same thing. Since the statements are themselves subjects — i.e., they are things that someone might want to talk about someday — they, too, must have subject proxies. If statements/relationships are represented as proxies, then …

… we need to know how to make them unique, too.
In the Methodology, an expression of a relationship is called an assertion.



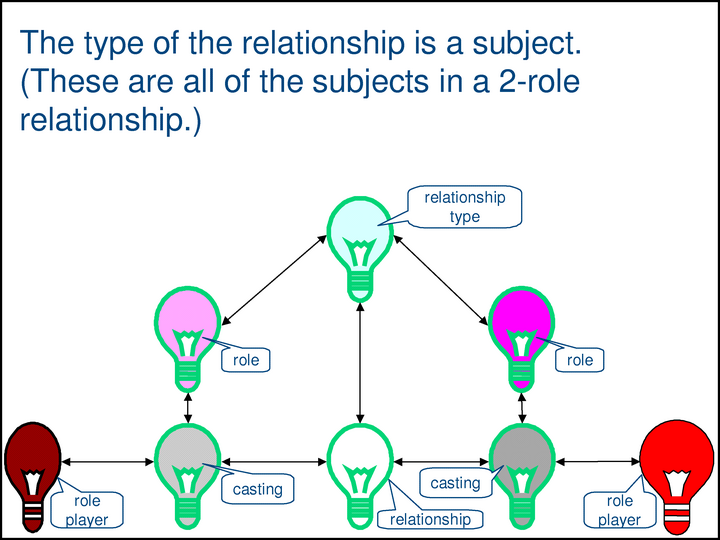
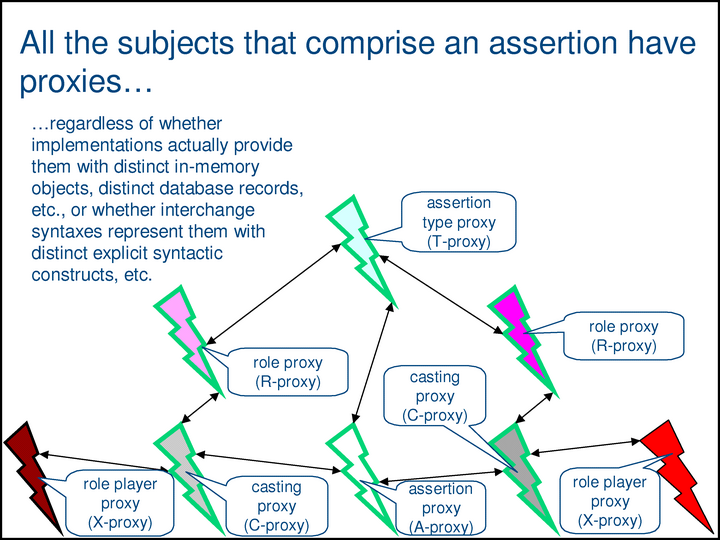
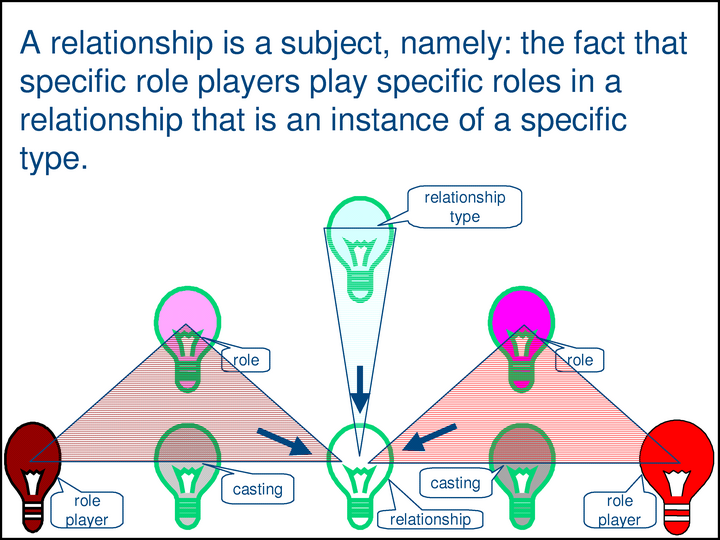
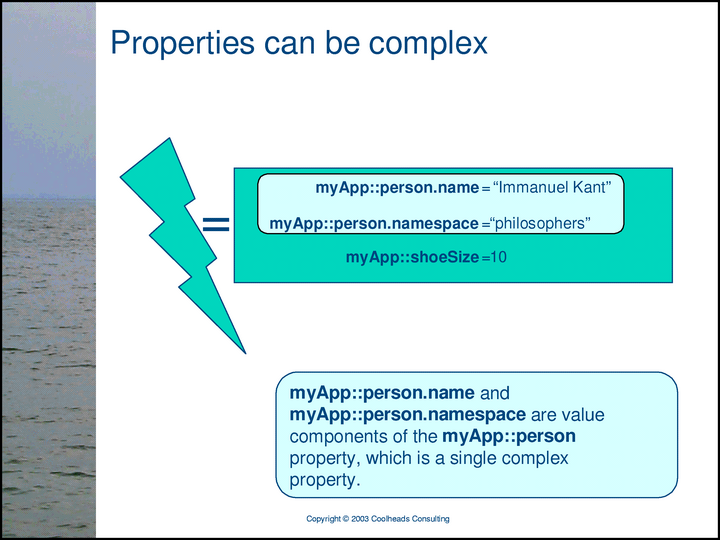
The green box shows a single complex property — the SIDP [Subject Identity Discrimination Property] of the a-proxy at the bottom center. The property has five components, the value of each of which is a proxy. The top component, a-sidp.t, is the type of the assertion. The rest are the role/role-player pairs of the assertion. Together, these components uniquely identify the subject of the assertion.
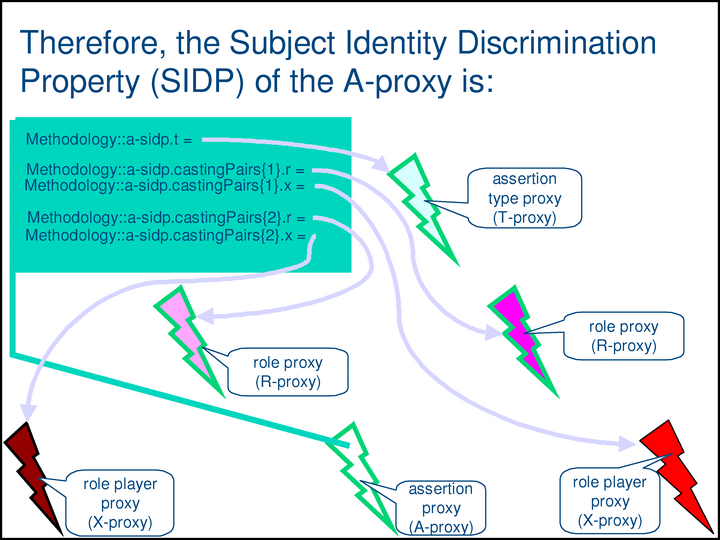
If two assertions have the same subject (i.e., they have equivalent SIDP values) …

… they are merged.

Since we can tell when two assertions are in fact saying exactly the same thing, …
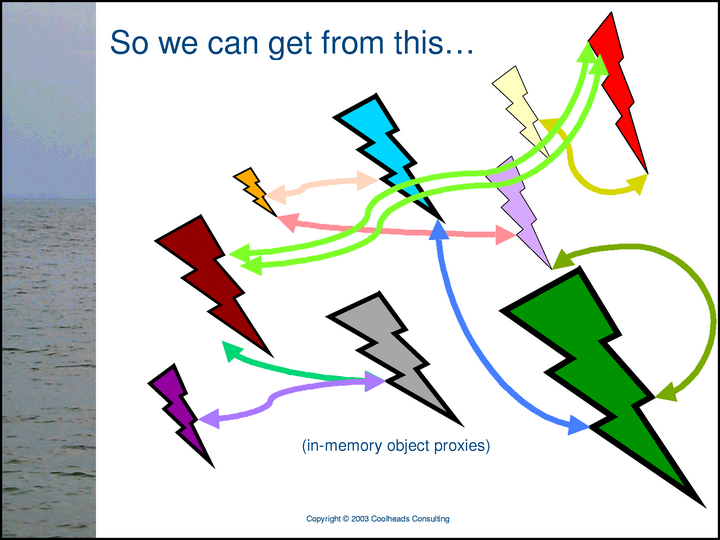
… we can eliminate the redundancy.
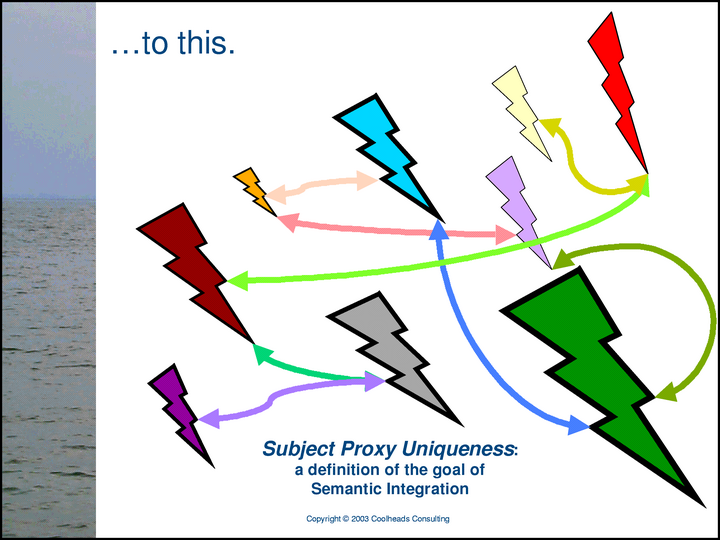






At its heart, the Methodology is a workable set of requirements for defining ontologies — “Applications” — that are intended to facilitate semantic integration. The Methodology demonstrates that it’s possible to codify the requirements, even at its very high level of abstraction. The requirements themselves turn out to be roughly equal in complexity to the requirements for defining a document schema: it’s not as simple as we might want it to be, but the complexity of the task is exactly as manageable as we decide to make it. In other words, the complexity of defining an ontology that supports semantic integration is proportional to the complexity of the integration that we’re trying to accomplish with it.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}