
![[AIB]](meschini_files/aibv72.gif) Associazione italiana biblioteche. BollettinoAIB 2005 n. 1 p. 59-72
Associazione italiana biblioteche. BollettinoAIB 2005 n. 1 p. 59-72L'annuale conferenza "unificata" dell'Association for Literary and Linguistic Computing (ALLC)1 e dell'Association for Computers and the Humanities (ACH)2, denominata comunemente ALLC/ACH,
č uno degli appuntamenti piů importanti nel settore dell'applicazione
delle nuove tecnologie alle scienze umane, disciplina in Italia ormai
definita informatica umanistica3 e nei paesi anglosassoni da tempo nota come humanities computing.
Organizzata alternativamente negli Stati Uniti e in Europa, l'edizione
del 2004 č stata ospitata dall'Universitŕ di Göteborg in Svezia4, mentre l'ALLC/ACH 2005 avrŕ luogo in Canada a Victoria, nel British Columbia5.
Da un punto di vista sia qualitativo sia quantitativo, il livello degli
interventi č molto elevato e l'evento risulta estremamente utile per
avere una visione generale delle linee di ricerca attualmente in corso
nelle varie aree disciplinari, dalla linguistica computazionale alle
biblioteche digitali, dalle applicazioni dei linguaggi di marcatura
all'analisi testuale, dai libri elettronici fino all'influenza delle
teorie narratologiche nello sviluppo dei videogiochi6.
All'interno della comunitŕ che si occupa di informatica umanistica un
ruolo sempre piů rilevante, sia per il peso scientifico sia per il
numero di persone coinvolte, č svolto dalla Text Encoding Initiative7
(TEI), un'associazione internazionale e interdisciplinare attiva dal
1987. L'ALLC/ACH stessa contiene al suo interno una sorta di "convegno
parallelo" della TEI, un incontro totalmente informale ma che risulta
un'ottima occasione per scambiare idee, confrontare progetti e opinioni
e fare in un certo senso il punto della situazione8.
Lo scopo principale della TEI č la definizione di uno standard per la
codifica elettronica dei testi letterari o, come vengono definite nel
sito Web ufficiale, delle «Guidelines for electronic text encoding and
interchange». Tali linee guida sono espresse tramite un linguaggio di
marcatura aderente nelle prime versioni alle specifiche SGML e dal
2002, come naturale evoluzione, a XML, con l'edizione P49.
La codifica TEI č ormai uno standard sempre piů utilizzato nei progetti di digitalizzazione full text, non solo per la validitŕ in sé delle specifiche e delle concrete possibilitŕ di utilizzo10, ma anche per la vitalitŕ e disponibilitŕ dei partecipanti, che tra gruppi di lavoro, gruppi d'interesse11 e mailing list
offrono un valido ed efficiente supporto a chiunque voglia adottare
questo linguaggio per i propri scopi. Chi ha avuto esperienze simili sa
benissimo che la marcatura di un testo č solo il primo dei tanti passi
che portano alla creazione di una biblioteca digitale. L'aspetto della
visualizzazione (pubblicazione) di un testo, per esempio, č attualmente
di primaria importanza. Prima dell'avvento del Web nel campo delle
risorse testuali elettroniche l'enfasi era posta sull'analisi e la
pubblicazione era vista come un fattore secondario.
L'avvento del WWW ha cambiato tutto, portando al primo posto la
visualizzazione, seguita dalle possibilitŕ di ricerca generali e infine
dalle analisi testuali specifiche, come concordanze ed estrazione di token.
Il fatto che il linguaggio TEI sia attualmente un "dialetto XML" rende
piů facilmente risolvibili tutti questi aspetti, perché č possibile
utilizzare diversi programmi open source in grado di manipolare
questo particolare formato. Quindi tra adattamenti specifici di
software nati in contesti piů propriamente "informatici" e programmi
sviluppati direttamente in ambito accademico e istituzionale12
le possibilitŕ sono decisamente piů numerose di quanto non fossero solo
qualche anno fa, quando la scelta obbligata era l'utilizzo di
applicazioni sě efficienti, ma proprietarie, complesse e costose come
Dynatext/Dynaweb.
Naturalmente in questo campo, cosě come in altri settori legati al
trattamento delle informazioni, appena un problema č non risolto ma in
via di risoluzione, si pongono subito altre questioni. Una delle piů
sentite riguarda il rapporto tra il testo elettronico e le informazioni
che lo descrivono, i cosiddetti metadati. Questo discorso č estendibile
a qualsiasi oggetto fatto di bit e non solo di natura testuale, anzi
nel caso di materiale multimediale una dimensione testuale č ancora piů
importante per consentire il dialogo tra le applicazioni e i computer,
per le funzioni di organizzazione, catalogazione, condivisione, ricerca
e reperimento. Con l'aumentare del numero di risorse digitali
disponibili, di qualsiasi tipo esse siano, non solo culturali o
testuali, aumenta l'importanza dei metadati associati. L'importanza e
anche il ruolo, non piů statico e di secondo piano, ma fondamentale e
dinamico. Cambiando il ruolo, cambia di conseguenza anche il tipo. Se
per attivitŕ "tradizionali", come la classificazione o la ricerca per
campi, č piů che adeguato il concetto di "metainformazione" cui siamo
abituati - al limite aggiornato con dati specifici al contesto digitale13, un tipo di informazione "gestionale-amministrativa-descrittiva-strutturale"14
- si avverte adesso anche l'esigenza di un altro concetto di metadato,
piů legato alla sostanza che alla forma dell'oggetto: un metadato
semantico, relativo ai contenuti, che permetta la creazione di reti di
conoscenza, di collegamenti basati sul significato tra i vari oggetti
digitali, e che possa trascendere l'appartenenza "fisica" di una
risorsa, in modo da potersi estendere virtualmente su tutta la rete.
Il motivo di tale esigenza č espresso perfettamente da Jean-François Lyotard in La condizione postmoderna.
Lyotard č dell'opinione che nei giochi a informazione incompleta, come
le societŕ precedenti la nostra, i vantaggi competitivi si ottengano
tramite l'acquisizione di un nuovo supplemento d'informazioni. Al
contrario, nei giochi a informazione completa o con un quantitativo
d'informazione sufficiente, come la societŕ contemporanea, una migliore
performance si ottiene per lo piů attraverso il collegamento di una
serie di dati ritenuti fino a un certo momento indipendenti15.
Il problema č quale tecnologia possa portare questi vantaggi
competitivi alle ormai numerose collezioni di testi digitali: occorre
qualcosa che sia comprensibile dalla macchina oltre che leggibile
dall'uomo e perfettamente compatibile in prima istanza con le
specifiche della TEI ed eventualmente con altri tipi di formati, sia
testuali sia multimediali. La codifica TEI, che segue la struttura ad
albero tipica dei linguaggi basati su XML, prevede due sottosezioni
principali: l'intestazione, contenente i metadati bibliografici,
amministrativi e gestionali del documento, e il corpo, con il contenuto
vero e proprio. Tali sezioni sono rappresentate rispettivamente dagli
elementi <teiHeader>16 e <text>.
Nella mia esperienza ho notato che chi proviene da un corso di studi
incentrato sulle materie letterarie in fase di codifica tende a
sottovalutare il <teiHeader>,
compilandolo quel tanto che basta e concentrandosi piuttosto sul
contenuto del documento, rischiando cosě di tralasciare informazioni
importanti17. D'altro canto queste
stesse persone sono estremamente interessate a un concetto di metadato
semantico, il quale perň per motivi sia tecnici sia di omogeneitŕ
strutturale non puň collocarsi all'interno dell'intestazione né del
contenuto.
Questo era uno degli argomenti piů attuali e discussi all'ALLC/ACH
2004, non solo durante gli interventi ufficiali ma anche e soprattutto
nelle chiacchierate informali che hanno luogo durante le pause tra una
presentazione e l'altra e nei break
per il pranzo. Chiunque abbia un minimo di esperienza di convegni sa
quanto questi scambi informali d'informazioni siano importanti per la
collaborazione e la ricerca scientifica. In queste discussioni si
finiva sempre per parlare delle tecnologie collegate al Web semantico,
con le immancabili citazioni dei vari RDF18, DAML19 e OIL20,
ma a essere nominata con maggiore frequenza e interesse non era una
sigla astrusa, bensě un'espressione suggestiva e facile da ricordare: topic map, letteralmente traducibile come mappa di argomenti.21
In questa breve porzione di un indice sono elencati in ordine alfabetico i nomi di alcuni argomenti (topic) e per ognuno di essi una o piů indicazioni del luogo in cui l'argomento viene trattato (occurrence),
utilizzando il numero del volume e delle pagine, insieme a delle
convenzioni tipografiche e delle sigle che servono a specificare
ulteriormente il tipo di occorrenza31,
come per esempio la presenza di un'immagine tramite l'utilizzo della
sigla "tav.". Un'altra informazione importante č quella relativa ai
collegamenti tra due o piů topic (association): alla
voce "Biblioláthas" la parola chiave "vedi" indica un collegamento con
"Didimo", anche se non vengono specificati né la natura del
collegamento né i diversi ruoli che hanno i due argomenti. Č prevista
anche la presenza di alcune varianti per il nome, vedi "Biblos" e
"Biblus" per "BIBLO", e la possibilitŕ di un'organizzazione gerarchica,
come nel caso di "Architettura" e "Biblioteconomia" per "BIBLIOTECA"32.
Naturalmente l'indice per nomi č solo una delle tante possibilitŕ,
poiché potrebbe essere organizzato anche per soggetti e luoghi. Le
componenti fondamentali di un indice sono gli argomenti, identificati
da uno o piů nomi, le associazioni tra di essi e le occorrenze di un
argomento. Ulteriori informazioni possono essere aggiunte specificando
la tipologia di ognuno di questi componenti. Topic, association e occurence
sono per Steve Pepper anche le componenti chiave del modello delle
mappe di argomenti, a cui aggiunge perň anche la possibilitŕ per un
argomento di avere una definizione, come nei glossari, e la
tipizzazione delle relazioni presente nei thesauri33.
Il concetto di topic č quanto mai generico e viene definito come la rappresentazione all'interno di una topic map di una qualsiasi cosa su cui possano essere fatte delle asserzioni. L'unica limitazione č che un topic
puň rappresentare uno e un solo argomento, qualunque esso sia. Data una
definizione di questo genere č evidente come sia possibile creare una
mappa a partire da qualsiasi tipo di informazione. Consideriamo la
seguente frase: «Sul Bollettino AIB č pubblicato Le mappe topiche di Federico Meschini». A prima vista gli argomenti (e di conseguenza i topic)
che si possono individuare sono tre: "Bollettino AIB", "Le mappe
topiche" e "Federico Meschini", o meglio questi sono i nomi, le
etichette da utilizzare come riferimento. Potrebbero perň essere
presenti delle varianti, come per esempio "Bollettino AIB: rivista
italiana di biblioteconomia e scienze dell'informazione", se prendiamo
in considerazione anche il sottotitolo, oppure "Mappe topiche (Le)" e
"Meschini Federico" ai fini di un'eventuale indicizzazione alfabetica.
Da questo possiamo dedurre che:
NOTE
[1] ALLC: Association For Literary And Linguistic Computing, <http://www.allc.org>.
[2] ACHWeb, <http://www.ach.org>.
[3] Per una definizione di informatica umanistica si veda Gino Roncaglia, Informatica umanistica: le ragioni di una disciplina, «Intersezioni» 23 (2002), n. 3, p. 353-376 . L'articolo č disponibile online all'indirizzo <http://www.merzweb.com/testi/saggi/informatica_umanistica.htm>.
[4] ALLC/ACH 2004, <http://www.hum.gu.se/allcach2004>.
[5] ALLC/ACH conference 2005, <http://web.uvic.ca/hrd/achallc2005>.
[6] ALLC/ACH 2004, sessione plenaria di chiusura: Espen Aarseth, Old, new, borrowed: blue? What can the humanities contribute to the games field?
[7] TEI: Text Encoding Initiative, <http://www.tei-c.org>.
[8] Il meeting ufficiale si svolge invece annualmente in autunno: <http://www.tei-c.org/Publicity/baltimore.html>.
[9] TEI P4: guidelines for electronic text encoding and interchange, XML compatible edition, edited by Michael Sperberg-McQueen and Lou Burnard 2004. Si veda <http://www.tei-c.org/P4X>.
[10] Gli abstract inviati dai vari partecipanti all'edizione del 2005 del convegno ALLC/ACH vengono "marcati" in TEI P4 cosě da ottenere dallo stesso documento sia il PDF per l'edizione a stampa sia l'HTML per il sito Web, tutto in un unico flusso di lavoro grazie alla tecnologia dei fogli di stile di trasformazione e di formattazione, XSLT e XSLFO.
[11] Definiti come working group e special interest group.
[12] Per un elenco di partenza vedi la TEI/CMS tool list all'indirizzo <http://miro.acs.its.nyu.edu/tei_cms/show.php>.
[13] Come per esempio il tipo di file, il quantitativo di memoria occupata, l'applicazione con cui č stato generato e quelle con cui puň essere utilizzato.
[14] E a questo scopo rispondono alla perfezione standard come METS <http://www.loc.gov/standards/mets/mets-home.html>, MODS <http://www.loc.gov/standards/mods>, o l'italiano MAG <http://www.iccu.sbn.it/schemag.htm>.
[15] Jean-François Lyotard, La condizione postmoderna, Milano: Feltrinelli, 1981, p. 95.
[16] Per una descrizione dell'elemento <teiHeader> e del suo contenuto si veda <http://www.tei-c.org/P4X/HD.html>.
[17] E questo sottolinea ulteriormente l'importanza del ruolo dei bibliotecari nei progetti di codifica e digitalizzazione.
[18] Resource Description Framework, <http://www.w3.org/RDF>.
[19] DARPA Agent Markup Language Homepage, <http://www.daml.org>.
[20] Ontology Inference Layer, <http://www.ontoknowledge.org/oil>.
[21] Il termine greco topos significa sia "luogo" sia "argomento".
[22] Questo "salto di livello" risolve i problemi legati alla struttura e alla compatibilitŕ con i vari formati.
[23] Mentre i database relazionali catturano le relazioni tra gli oggetti informativi, spesso inglobandoli al loro interno, le topic map creano dei collegamenti tra questi oggetti senza alterare la loro posizione. Un articolo interessante che confronta i due modelli č Alexander Johannesen, Here is a how to topic maps, Sir!, <http://shelter.nu/art-007.html>.
[24] Sono notevoli le somiglianze con modelli nati in altri ambienti legati per esempio alle scienze cognitive, come le mind map, le "mappe mentali", teorizzate dallo psicologo Tony Buzan, <http://www.mind-map.com>.
[25] HyTime, <http://www.hytime.org>, la sintassi precedentemente usata per descrivere il modello delle topic map, utilizzava SGML, mentre XTM (XML Topic Maps, <http://www.topicmaps.org/xtm/1.0>), quella attualmente piů diffusa, segue le regole di XML. Esiste inoltre un altro tipo di notazione, LTM (Linear Topic Map Notation, <http://www.ontopia.net/download/ltm.html>), sempre basata su un formato testuale ma che non utilizza la sintassi dei linguaggi di marcatura.
[26] Steve Pepper, The TAO of topic maps: finding the way in the age of infoglut, 2002, <http://www.ontopia.net/topicmaps/materials/tao.html>. Per un elenco di altri articoli e materiale introduttivo si veda Topic map articles, <http://www.topicmap.com/topicmap/resources.html#introductions>.
[27] Il termine č alla base della filosofia cinese taoista, teorizzata da Lao Tzu nel suo Libro della via e della virtů. Edizione in lingua italiana di riferimento Lao Tzu, Tao te ching, Milano: Mondatori, 2001. Il testo č disponibile in edizione elettronica sul Web sia in italiano, <http://www.liberliber.it/biblioteca/l/lao_tzu/index.htm>, sia in cinese <http://www.chinapage.com/laozi724.html>.
[28] Sam Hunting puntualizza che nel reference model, il modello concettuale di riferimento, č piů corretto parlare di rapporti tra assertions, topic, occurence, topic, base name, base name e variant name, ammettendo perň che ATOTBBV ha molto meno potere evocativo di TAO: Sam Hunting, The rise and rise of topic maps, in XML topic maps: creating and using topic maps for the Web, Jack Park and Sam Hunting editiors, Boston: Addison-Wesley, 2002, p. 65.
[29] Steve Pepper, The TAO of topic maps cit.
[30] Tratto da Grande dizionario enciclopedico UTET, v. Indice – Atlanti, Torino: UTET, 1975, p. 110.
[31] Utilizzando un'espressione piů appropriata e mutuata dall'informatica si potrebbe parlare di tipologia dell'istanza.
[32] Sempre utilizzando il gergo informatico in questo caso si parla di rapporto tra classe e proprietŕ della classe.
[33] Organizzate in base alla tipologia del nome (come per esempio verbo, sostantivo e aggettivo) oppure su base semantica (la relazione per contrari).
[34] In una relazione di tipo classe-istanza.
[35] Potendo cosě utilizzare questo modello per aggiungere informazioni su di loro.
[36] Anche queste naturalmente vanno definite come topic.
[37] Consideriamo solo la semantica di queste affermazioni e non la struttura grammaticale. Quindi sarebbe equivalente scrivere "Le mappe topiche č pubblicato sul Bollettino AIB".
[38] Nulla vieta di utilizzare altre categorie e di conseguenza altri topic, magari di ambito piů generico, come per esempio "contenitore" e "contenuto".
[39] Nel caso delle risorse elettroniche presenti in Internet si utilizzano gli URI/URL.
[40] Che possono essere identificati a loro volta dai topic "edizione cartacea" ed "edizione elettronica".
[41] A sua volta identificato da un topic.
[42] Traducibile come "identitŕ di argomento".
[43] Come nel caso delle risorse dotate di URI. Per il topic "Bollettino AIB" potrebbe essere la pagina principale del suo sito Web: <http://www.aib.it/aib/boll/boll.htm>.
Steve Pepper, The TAO of topic maps cit.
[44] Steve Pepper, The TAO of topic maps cit, <http://www.ontopia.net/topicmaps/materials/tao-asstypes.jpg>.
[45] Steve Pepper, The TAO of topic maps cit, <http://www.ontopia.net/topicmaps/materials/tao-asstypes.jpg>.
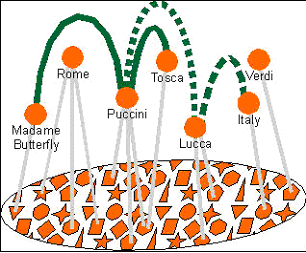
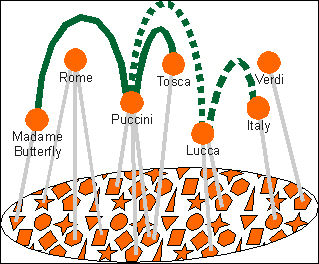
[46] Madame Butterfly, Roma, Puccini, Tosca, Verdi, Lucca ecc. Il riferimento č naturalmente all'opera. Questo esempio č poi sviluppato da Pepper sino a divenire un'applicazione completa, The Italian opera topic map, di cui si parlerŕ in seguito.
[47] Si veda Jack Park-Nefer Park, Topic maps in the life sciences, in XML topic maps: creating and using topic maps for the Web cit., p. 149-166.
[48] HyTime, <http://www.hytime.org>.
[49] Standard Generalized Markup Language, il linguaggio di marcatura da cui ha avuto origine HTML <http://www.w3.org/MarkUp/SGML>.
[50] Si veda il documento ISO/IEC 13250 topic maps, disponibile all'indirizzo <http://www.y12.doe.gov/sgml/sc34/document/0322_files/iso13250-2nd-ed-v2.pdf>.
[51] Extensible Markup Language, <http://www.w3.org/XML>.
[52] TopicMaps.org, <http://www.topicmaps.org>.
[53] XML Topic Maps (XTM) 1.0, <http://www.topicmaps.org/xtm/index.html>.
[54] Document Type Definition, uno dei modi con i quali č possibile stabilire la grammatica, le regole di sintassi, di un linguaggio basato su XML. La DTD di XTM č disponibile in linea: <http://www.topicmaps.org/xtm/xtm1.dtd>.
[55] Xpath, <http://www.w3.org/TR/xpath>, viene utilizzato per selezionare parti di un documento XML, rappresentato come una struttura ad albero. Xlink, <http://www.w3.org/XML/Linking>, permette di creare collegamenti tra le risorse, dai semplici link ipertestuali unidirezionali a funzionalitŕ piů avanzate. XPointer, <http://www.w3.org/TR/xptr>, basato in buona parte su XPath lavora in coppia con XLink per puntare a sezioni specifiche di un documento XML.
[56] L'elemento (o marcatore) č alla base del concetto di linguaggio di marcatura. Si tratta di un elemento etichetta che contemporaneamente delimita le informazioni racchiuse al suo interno.
[57] Un attributo aggiunge informazioni all'elemento di cui fa parte. In XTM č presente l'attributo id che serve ad identificare in maniera univoca un elemento all'interno di un documento XML. Sono presenti altri due attributi, xlink:href e xlink:type, ma sono relativi ad XLink.
[58] Sul Web, oltre naturalmente alle specifiche ufficiali, sono disponibili dei tutorial, Anitta Altenburger, Authoring XTM topic maps, 2000, <http://topicmaps.it.bond.edu.au/docs/6/toc>, e Michel Biezunski, The XTM guide: a beginner's guide to the XTM syntax, 2005, <http://www.infoloom.com/xtmguide.htm>.
[59] Tutte queste informazioni sono espresse nella DTD.
[60] <http://www.topicmaps.org/xtm/1.0/language.xtm> e <http://www.topicmaps.org/xtm/1.0/country.xtm>.
[61] Omnigator, <http://www.ontopia.net/omnigator/models/index.jsp>.
[62] Ontopia: the topic map company, <http://www.ontopia.net>.
[63] Nell'ultima versione supporta anche RDF. Č stato inserito anche il Vizigator, un visualizzatore grafico di topic map.
[64] Il codice č disponibile sia in XTM <http://www.ontopia.net/omnigator/docs/navigator/opera.xtm> sia in HyTime <http://www.ontopia.net/omnigator/docs/navigator/opera.hytm>.
[65] <http://www.ontopia.net/omnigator/models/topicmap_complete.jsp?tm=opera.xtm>.
[66] OperaMap: the Italian opera topic map, <http://www.ontopia.net/operamap/index.jsp>.
[67] The Ontopia Knowledge Suite (OKS), <http://www.ontopia.net/solutions/products.html>.
[68] Ontopia solutions: Navigator framework, <http://www.ontopia.net/solutions/navigator.html>.
[69] E in quest'ultimo caso decisamente piů amichevole.
[70] DRH 2004, <http://drh2004.ncl.ac.uk>.
[71] John A. Walsh, Topic maps and TEI-encoded literary texts. Abstract disponibile sul Web: <http://drh2004.ncl.ac.uk/abstract.php?abstract=177>.
[72] The Swinburne project, <http://www.letrs.indiana.edu/swinburne>.
[73] Avirel: archivio viaggiatori italiani a Roma e nel Lazio, <http://www.avirel.it>.
[74] Codificati nel formato TEI e resi disponibili in HTML tramite XSLT, i fogli di stile di trasformazione di XML, <http://www.w3.org/TR/xslt>.
[75] Biblioteca digitale Avirel, <http://www.avirel.it/bd/index.htm>.
[76] <http://www.avirel.it/cocoon/avirel_tm/avirel_tm.html>
[78] Si tratta dello stesso documento contenuto nella Biblioteca digitale, evitando qualsiasi tipo di ridondanza.
[78] All'indirizzo <http://www.avirel.it/cocoon/avirel_tm/avirel_tm.xml>. La generazione di tutte le pagine HTML č effettuata utilizzando i fogli di stile XSLT , applicati dinamicamente al file XML tramite Cocoon, un potente framework di pubblicazione open source sviluppato dal gruppo Apache, <http://cocoon.apache.org>.
[79] Cosě vengono definite le applicazioni aziendali di una certa entitŕ.
[80] Per un elenco completo si veda Topic map vendors, <http://www.topicmap.com/topicmap/vendors.html>.
[81] Acronimo di Topic Maps for Java, <http://tm4j.org>.
[82] Esempi di questa corrispondenza sono presenti sia nel codice di The Italian opera topic map sia di Swinburne topic map.
[83] RDF topic map mapping, <http://www.w3.org/2002/06/09-RDF-topic-maps>.
[84] Durante l'ALLC/ACH 2005 tre interventi saranno incentrati sull'utilizzo delle topic maps: Federico Meschini, Classifying the Chimera; John A. Walsh, TM4DH (Topic Maps For Digital Humanities): examples and an open source toolkit; Christian Wittern, From text to topics: zigzagging towards the knowledgebase of tang civilization. Informazioni <http://web.uvic.ca/hrd/achallc2005/abstract_list.htm>.
[85] Come il progetto Topic Map Application Programming Interface (TMAPI), <http://www.tmapi.org>, o lo sviluppo dei linguaggi Topic Map Query Language (TMQL), <http://www.isotopicmaps.org/tmql>, e Topic Map Constraint Language (TMCL), <http://www.isotopicmaps.org/tmcl>. Un elenco degli strumenti č disponibile all'indirizzo Topic map tools, <http://www.topicmap.com/topicmap/tools.html>.
[86] SWBPD: RDF/Topic maps interoperability task force description, <http://www.w3.org/2001/sw/BestPractices/RDFTM>.
[87] Si veda per esempio Eric Freese, Topic maps and RDF, in XML topic maps: creating and using topic maps for the Web cit. p. 283-324; Lars Marius Garshol, Living with topic maps and RDF, <http://www.ontopia.net/topicmaps/materials/tmrdf.html>; Martin S. Lacher – Stefan Decker, On the integration of topic maps and RDF , <http://www.semanticweb.org/SWWS/program/full/paper53.pdf> e gli articoli presenti nella sezione The relationship between RDF and topic maps <http://www.techquila.com/topicmaps/tmworld/11902.html> del sito Techquila: standards-based information management, <http://www.techquila.com>.
[88] John Gartner, Searching smarter, not harder, 2004, <http://www.wired.com/news/technology/0,1282,65840,00.html?tw=newsletter_topstories_html>.
[89] Sam Hunting, How to start topic mapping right away with the XTM specification, in XML topic maps: creating and using topic maps for the Web cit. p. 82-83.
{kind=link}