The project concerns the electronic edition of teaching texts produced in the University of Medicine and Arts of Bologna in the 14th century. The decision of producing an electronic critical edition of the entire corpus follows by necessity from the very nature of the texts. Common teaching practices, such as the repetitio, affected their production and transmission, causing each witness to be substantially different from the others. A reconstruction of the text by means of standard collating procedures is therefore impossible, whereas a database representation of the entire textual tradition seems to be best suited to the 'fluid' nature of the texts, offering the most rewarding approach to their critical analysis.
A prototype edition of the first lectio of the commentary by Gentilis de Cingulo of Porphyry´s Isagoge (first decade of the 14th century) has so far been produced by means of the DBMS 'kleio', developed by Manfred Thaller at the Max-Planck-Institut für Geschichte in Göttingen. The transcriptions have been structured as a database and the system allows the binding of structured portions of the text with the relevant parts of the digitized images of the manuscripts. Parallel passages of the text, together with their images, can be retrieved addressing queries either to the transcriptions or to the images. Further developments of the system will soon enable the handling of non-linear segments of the text ('enhanced strings' made up of sequences of characters and portions of bitmap), allowing therefore for the treatment of textual variants.
Image processing has turned out to be of great help in a project concerning the critical edition of teaching books produced in the university of medicine and arts of Bologna in the late Middle Ages. The decision of producing an electronic critical edition of these texts was prompted by the recognition of the common nature of their textual tradition. The transmission of these texts and their physical production was heavily affected by common teaching techniques such as repetitio. A characteristic figure in the Bolognese scholastic tradition was in fact the repetitor, "a young master who acted as a teaching assistant for the master appointed to the ordinary course, with the special duty to 'repeat' to the students in the evening the lecture given by the master in the morning"( B MB, 643).[1] Traces of the activity of these repetitores are preserved in the manuscripts, mainly under the form of anonymous marginal glosses or even long passages interpolated within the text, but reported only by few or even one copy. As a result, "the works of the Bolognese masters of philosophy and medicine in the 14th century are often characterized by a complex textual tradition, providing evidence for a gradual process of composition through the different interventions of the master himself and of his repetitores. Hence, these texts also usually exhibit a sort of 'fluidity', affected as they are by a great number of alternative readings, scattered through the different manuscript copies, and by glosses and additions which can even be peculiar to each copy"( B MB, 644(a)).
A typical case of this kind is the commentary on Porphyry´s Isagoge written in the first decade of the 14th century by the Bolognese master Gentilis de Cingulo, the work we first started to transcribe. The text is witnessed by four manuscript copies exhibiting some major discrepancies, such as glosses and interpolations, which do not characterize however different redactions of the work.
For a text of this kind , "the traditional goal of assessing the text in the most reliable way", that is through a critical edition based on the canonical printed book model, "could be neither feasible nor desirable". For, "it is often not easy to decide whether a gloss or an addition stem from a later intervention by the author himself or by a repetitor (and, in the latter case, whether the repetitor is merely repeating his master´s doctrines or is speaking on his own authority)". Moreover, "for the purposes of our research project, which is focussed on the early institutional framework of the study of arts and philosophy in Bologna, all the different versions of a text are of the same historical relevance"( B MB, 644(b)).
How could then a good critical edition be produced? The 'fluid' nature of the textual tradition of Gentile´s commentary was interposing a major stumbling block. How could we construct a critical text? Was it, in our case, the very idea of making clear-cut choices based upon collation a viable one, or even a sound one? The usual procedures of text construction did not look totally appropriate any more. It was at this point that we came across the idea of a database representation of the entire textual tradition, and we saw it as a possible way out of our difficulties. And it should also be stressed that in our case computers and information processing were offering a solution to a difficulty that could have hardly been met otherwise. Computers and information processing were taking us a step further in our own disciplinary domain, by enabling a methodological advance in textual criticism itself.
A provisional solution was found in the idea of producing encoded diplomatic transcriptions of all our manuscript witnesses. The TEI guidelines were not yet completed, but we thought we would have soon been able to refer to their recommendations. Our encoded transcripts, then, could have been stored in a database, and we would have been able to retrieve and analyse all necessary information.
That solution was immediately superseded as soon as we realized that we could avail ourselves of digital images and that we could appeal to a system capable of processing both digitized images and their transcriptions, such as the 'kleio' database management system developed by Manfred Thaller at the Max-Planck-Institut für Geschichte in Göttingen.
The availability of digitized images made us rethink the function of a diplomatic transcription and, for that matter, of a transcription altogether. Diplomatic transcriptions could be conceived no more as a substitute for the original, but as a form of analysis of the information contained in it; they could more properly serve the purposes of further processing. Transcribed information, diplomatically or otherwise, could be further processed, and computers were enabling further analytical advances.
With a system such as 'kleio', which provides image processing facilities, the images themselves could be dealt with as logical information, as additional data integrated into the database. Images were not supplied any more as simple illustrations, but could be processed to improve readability, or to be associated with their corresponding transcriptions.
From this point of view, "both the image and the transcript" were no more "regarded as physical reproductions referring back to the original document, but rather as analytical data pointing toward a new logical representation of the source"( B IP, 148(a)). The idea of conceiving both the transcription and the image as a logical representation of a manuscript source led us to reconsider the notion itself of an edition. Computers could provide new forms of representing a manuscript text. They were not providing only an aid to expeditiousness, or a means of coping with very large amounts of data; they were affording a way out of the snares of the printed edition, where the classical model of textual representation could not cope. We could appeal to computers for a new form of representation, precisely to overcome critical problems of textual representation.
An edition whatsoever is a form of textual representation and the model we had could not solve our difficulties. But digitized transcriptions and images were now thought of as a form of logical representation and they could be put to a different purpose; they could now serve not only as a physical reproduction of a manuscript, but rather as a new conceptual representation of its content. They could be used not as a representation of a document, but as a representation of a text. Digitized images and transcriptions are documents themselves, a particular form of representation. Why should they be used to represent other documents, other forms of representation, and not the text? Could they not provide a new logical form of representing the text? So we decided to use digitized images and transcriptions not to replicate a manuscript or a printed edition in a new physical medium; we took them as new forms of textual representation, on a par with any other form, be it a manuscripts, or be it a printed book. As a form of textual representation, an edition is a document, not a text; precisely in the same way, digitized images or digitized transcriptions, as a form of representation of an information content, are data, not the information they convey. But data are processable, and processing is analysis. A database representation of a textual tradition contributes to its critical analysis in a way that overcomes the limitations of the printed model of textual representation.
The limitations of the printed edition, the classical model of textual representation, are obvious in a number of cases. One is the case of handwritten "drafts" or outlines with alternative readings left over by the author in a fragmentary state. In this case, the very placing and spatial arrangement of different portions of the text are very important and "the process of becoming a textual structure is there fixed in the spacial relations of chronologically different, but structurally equivalent textual units"( K EP, 110-11(a)).[2] How shall one reproduce in a printed edition the fragmentary nature of a text that shows itself "in the language of his spacial semantics"( K EP, 110-11(b))? A possible solution would be a diplomatic transcript and the use of diacritic marks. But "in the age of reproducibility, the attempts to represent manuscripts through description or special signs" can be seen as "an anachronism, if not a charicature of philology"( K EP, 150). Facsimiles have substituted for diacritics, but again "the distinction between physical and logical representation of a document, or between its mere reproduction and its analysis, must be carefully kept in mind"( B IP, 148(b)). For "it is only through the apparatus", that is to say through a logical representation or a due analysis, "that the facsimile - and finally the very manuscript itself - becomes capable of asserting" its information content ( K EP, 157). "Editing a manuscript remains categorially different from simply imitating it"( K EP, 111).
Another example is provided by the textual tradition of 12th- and 13th-century romance literature. As has been observed, "most of us almost automatically equate texts with printed books"( U OFM, 157(a)), but the medieval idea of textual canonicity "includes both the notion of 'authorship' and a variable textuality reflecting scribal 'creativity' and refashioning"( U OFM d, 10).[3] The medieval text is "fluid and dynamic", for "fidelity to an author´s work generally involves what we would call changing what the author wrote"( U OFM, 157-58(a)). But as reproduced in a printed book, text is fixed and immutable: again, "the form of representation is mistaken for the form of what is to be represented"( B IP, 148(c)). To keep closer to the varied and diversified nature of medieval textuality, the study of the Old French manuscript tradition pertaining to Chrétien de Troyes´ romance Chevalier de la Charrette (Lancelot) has been approached, in a project carried out at Princeton University, through the creation of a database including an encoded diplomatic transcription of all the extant manuscripts. However, "the methodological significance of a computer representation does not lay so much in its mimetic, as in its structural and logical features, which make sources available as data for further processing and analysis"( B IP, 149(a)). The "organizing power" of a database representation, is able "to augment the resources open to scholars" because it increases their options "in regard to analysis"( U OFM, 157-58(b)).
A wealth of very similar cases is handed over to us by that kind of 'fluid' tradition that is typical of the teaching books produced in the university of medicine and arts of Bologna in the late Middle Ages. In such cases, the practice of teaching and repetitio made the text vary and evolve with its own tradition; the role of the author gradually fades away and is sometimes reduced to a purely eponymous function with respect to a freely developing tradition. Here again we have to cope with a different kind of textual canonicity, "where alternative readings cannot be debased to lower-rank variants"( B IP, 149(b)).
In all these cases the appropriate editorial policy is almost mandatory: "also the so called alternatives are [to be] edited as 'text'"( K EP, 110). A database provides the obvious solution to such a problem and from the idea of a database as edition [4] we came upon the idea of an edition as database (Cf. BT ICT, B MB). But then we have to face a new theoretical challenge. Clearly such an 'edition', or more precisely a complete archive organizing all the information conveyed by all the manuscript witnessess of the text, "will be something different to a printed edition also from a theoretical point of view"( O IU, 142). But can we legitimately say that "the correct memorization of the text of the manuscripts such as it is, combined with the possibility of querying and analysing them through automated systems, can to advantage substitute for the so called critical edition in the traditional sense"( O IU, 144) ? Before we try to give an answer to this question, let us briefly describe the 'Gentile database', the prototype we have so far built for our commentary.
How was the database designed and what use was made of digital imaging? Let us recall the description we have given elsewhere:
"The 'kleio' database management system was chosen because it can administer images as a data-type, together with other more conventional data-types such as full text and structured alphanumerical data, all in the same processing environment (Cf. T KDBS, J IAS, WD TK, T SODP). Within the system, images can be connected to textual descriptions and/or transcriptions organized as structured elements of a database. The transcriptions were arranged accordingly in a kind of hierarchical database, following the internal structure of the text. The commentary is divided in a principium (which is lacking in ms. S) and seventeen sections corresponding to an equal number of lemmata of Porphyry´s text in the Boethian translation. Each lemma of the literal commentary comprises a divisio textus and a brief exposition of the sententia auctoris, followed by the discussion of notabilia and dubitationes (Cf. BT ICT, 190). We therefore obtained, for the first lectio, the following (simplified) structure (Fig. 1):
Text
________________________________________|_________________________________________
| | |
Lemma Accessus Lectio
_____________________|______________________________ ______________|______________________
| | | | | | | | | | |
Introductio | Causa formalis | Causa finalis | Partitio Divisio Dubium Littera Notandum
| | | | | | |
Causa materialis | Causa efficiens Titulus | ___|_______ |
| | | | | |
| | | | | |
Caput Caput Caput Quaestio Responsio Caput
| |
| |
Sub-caput Sub-caput
- Fig. 1 -
Because the structure is the same for each of the four manuscripts (F, M, C, S), we obtained the following (simplified) matrix (Fig. 2):
Mss. F M C S
________ _______ _______ _______
Lemma |________| |_______| |_______| |_______|
Accessus |________| |_______| |_______| |_______|
Introductio |________| |_______| |_______| |_______|
Causa materialis |________| |_______| |_______| |_______|
Caput |________| |_______| |_______| |_______|
Sub-caput |________| |_______| |_______| |_______|
Causa formalis |________| |_______| |_______| |_______|
Caput |________| |_______| |_______| |_______|
Causa efficiens |________| |_______| |_______| |_______|
Causa finalis |________| |_______| |_______| |_______|
Titulus |________| |_______| |_______| |_______|
Partitio |________| |_______| |_______| |_______|
Lectio |________| |_______| |_______| |_______|
Divisio |________| |_______| |_______| |_______|
Dubium |________| |_______| |_______| |_______|
Quaestio |________| |_______| |_______| |_______|
Responsio |________| |_______| |_______| |_______|
Littera |________| |_______| |_______| |_______|
Notandum |________| |_______| |_______| |_______|
Caput |________| |_______| |_______| |_______|
Sub-caput |________| |_______| |_______| |_______|
- Fig. 2 -
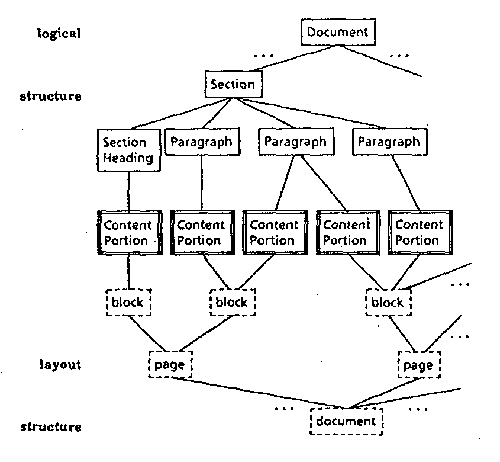
Every portion of the text in each of its four manuscript witnesses was then defined as the value of a structural element of the database, thus enabling us to connect it with the corresponding portion of an image. The main image files are bitmaps of a manuscript page, recto and verso of a manuscript folio, respectively. By means of the image processing facilities of the system, we could obtain from each image relevant cuttings for each portion of the text. The resulting structure for each sequence of textual units within a given manuscript can be represented by two independent tree structures built from these primitive units, very much the same as in an ODA (Cf. ISO ODA) [5] conformant model (Fig. 3; Fig. 4).
- Fig. 3 - [6]
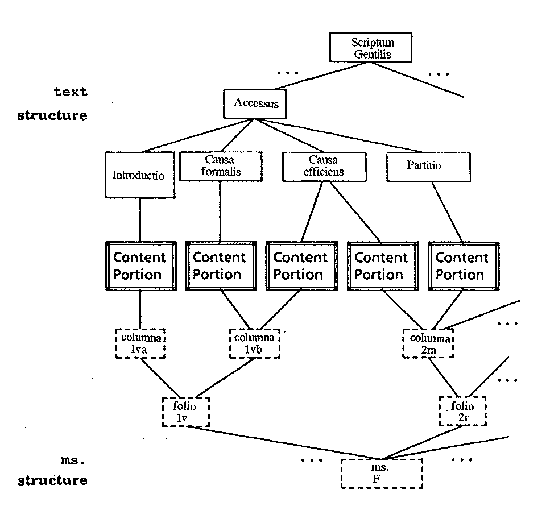
- Fig. 4 -
Images of parallel sections of the text can all be displayed on the screen, together with the relevant transcriptions. The editor can then assess parallel readings witnessed by different manuscripts in their actual context, displaying as much factual information as is needed"( B IP, 150(a)).
But now, is a database representation of an entire textual tradition "just an aid to the critical reconstruction of the text, or may it be considered as a step towards a new form of edition"? We have answered that, indeed, it serves both purposes. For "by means of a database management system (DBMS), information can be both processed and represented"( B IP, 150(b)), and precisely for that reason a computer based edition can be "open-ended"( U OFM, 157(b); G EDT, 159(a)) and "dynamic"(Cf. T BMV). And in fact the 'kleio' database management system "is a tool for processing information (in our case, for retrieving evidence, both textual and visual) and inferring analytical results (in our case, for making editorial decisions), as well as a means to represent both the data and the result of their processing (in our case, an entry in the apparatus and a reconstructed text). The enormous advantages afforded by the image processing facilities provided by 'kleio' to improve readability and asses unclear manuscript evidence are hardly to be underestimated; but it is its power in representing and organizing both evidence and results (in our case the very process of documenting and reconstructing a text) that better suits the purpose of producing an edition"( B IP, 150-51).
So why should a textual scholar still want to "stress", indeed undeniably, that a database "is not an edition"( U OFM d, 15) ? It is a claim, in our opinion, that has to be accepted, if a database is only thought of as a form of "replicating" a manuscript tradition ( U OFM, 157(c)). Indeed, "a database is by no means an edition as long as it is thought of as a sheer duplicate of its source material"( B IP, 151(a)), and there is a point in rejecting the notion of "a new type of edition"( K EP, 15), a so called "archive edition", whose task would comprise the "archival survey of all witnesses, and thus of all variants, both in the composition and transmission of the text", a sort of "inventory", conceived "primarily", and "in the sense of modern information theory", as "an information bearer"( K PvK, 19), that would "substitute for the originals under consideration"( K PvK, 40-41). And, after all, also an image "is only the best logical approximation to a document, and not a substitute for it".
But a database "had better be thought of as a structured logical representation of the sources", and here is our answer to the problem. "An information bearer, whichever it may be, cannot be just a replicate of the original: the problem is indeed to put its logical features to a good use. But how, exactly, can that be done, for the sake of producing an 'edition'? The most plausible answer appears to be to organize a database as an apparatus. For that seems to be precisely what makes an edition - not just an archive - out of anything"( B IP, 151(b)). Representing in database form "with commentary"( U OFM, 157(d)) a textual tradition is already translating encoded textual features into structures( P CD, 161). And that could possibly be done just for the sake of documenting one or another reconstruction of the text, which is precisely the purpose an apparatus is created for. It is also the problem our 'Gentile database' has to face: its claim to be a step towards a sound "critical edition in electronic form"( BT ICT, 193) very much depends on its solution to this problem.
As it as been stressed, an edition connot simply comprise a comprehensive, all-inclusive archive. An editor has to make choices, evaluating and discarding irrelevant factual information. To allow selections and new arrangements of textual material the editor should be able to provide for alternative structural representations of the text. And in order to do that its database management system shoud be endowed with adequate text processing tools powerful enough to handle alternative and possibly overlapping hierarchical structures of the same data.
Another requirement for a database to serve as an edition would be the publication of its structured data. A database can be thought of as an edition not because of its content of mere transcriptions and images, but for the way they have been organized and given a certain structure. It is the apparatus that matters, the result of the editor´s choices and analysis. It is stuctured data that have to be made publicly available. Digitized images and transcriptions are of interest, as an organized database, only if they can be merged with others as structured data. Only as structured data they can be 'quoted' or referred to as an edition from one database to another.
To meet these requirements two important developments of the 'kleio' database management system look very promising. Their architecture has already been designed and their implementation is in progress. The first of these developmens concerns the idea of a text engine, that is based on the notion of historical text (Cf. T PM). The notion of an "historical text engine"( T PM, 57ff) is connected with the idea of a "dynamic edition", a "potentially new technique for the dissemination of manuscript materials", a new form of edition "radically different from the notion of the classical printed edition"( T PM, 52(a)), an edition that is "open-ended" and "continuous"( G EDT, 159(b)), potentially "never finished", as opposed to a "static" and immutable one( T PM, 52(b)). From this point of view, the edited text of a documentary source, the text that constitutes the object of historical research, the "historical text" as it is called by Manfred Thaller, can be defined as "the formally treatable representation of the current assumptions of a researcher about what his documents actually contain"( T PM, 55-56). Hence the "dynamic edition of an historical text tends to approximate to that form of representation of the 'hermeneutic invariant' of a text that better suits the new exegetical practices enabled by the formal processing of textual data"( B HS, 187).
An historical text engine can then provide a mechanism for the formal treatment of enhanced strings, a new "fully integrated data type", comprising "a mixture of ASCII characters and arbitrary portions of bitmaps"( T PM, 54). Such a form of representation of textual data can take into account "several layers of traditions" and allow "a given portion of text to have more than an equally valid form". An historical text engine can enable a database management system to process just one "coherent" machine readable representation of a textual tradition, either comprising a single manuscript, or "the logical sum of two or more manuscripts". Thus it can "not only make it possible to handle variants, but to treat all streams of tradition combined into a 'text' as potentially equal". In general it allows "to define the relationship between a 'text' as a running representation of a tradited document and a 'text' as converted into a database according to some abstract model", so as to serve the purpose of reconstructing a text and organizing its critical apparatus ( T PM, 56-57).
The second development of the 'kleio' database management system concerns the idea of a Self-Documenting Image File, or SDIF(Cf. T SDIF). In a nutshell, SDIFs are to be thought of as an extension of the Tagged Image File Format (TIFF), especially designed to allow the import and export of portions of organized data to and from different database management systems. Besides the techncal description of the "physical characteristics" of a bitmapped image as provided by a TIFF file, SDIFs would contain "all the information necessary to understand the description of the image contained within it"; they would integrate the "historical description of the meaning of an image" with "the technical description of its physical properties". Exchanging SDIFs between different systems would allow scholars to export from an archive those portions of the organized materials that are relevant to their work, recombining them on a local machine into "one consistent database"( T SDIF, 138-40). In our case, images and their transcripts could be exchanged together with their own editorial apparatus. All in all, we may conclude that "the SDIF proposal lends itself as a valid theoretical solution for the dissemination and the distributed usage - the publication, in good substance - of a database representation of texts handed down to us by all sorts of fluid manuscript traditions"( B HS, 190).
[1] On the problem of repetitiones in Bologna and in other Italian universities see M UT, 55-62. [ Back to text ]
[2] H. Kraft, Editionsphilologie, Darmstadt, Wissenschaftliche Buchgesellshaft, 1990, pp. 110-111. This particular remark was brought to my attention by Claus Huitfeldt in discussions at the Wittgenstein Archives in Bergen. [ Back to text ]
[3] This and some subsequent quotations refer to a draft copy kindly conceded by the author. [ Back to text ]
[4] Cf. Halbgraue Reihe zur Historischen Fachinformatik, Serie C: Datenbasen als Editionen, hrsg. v. M. Thaller, St. Katharinen, Max-Planck-Institut für Geschichte i.K.b. Scripta Mercaturae Verlag. The series aims at "promoting secondary analys of materials in machine-readable form", by enabling access to materials "that usually could be obtained only under licence of archival institutions for texts and data". [ Back to text ]
[5] On representation problems of structured documents, see J DR. [ Back to text ]
[6] From F CM, 13. [ Back to text ]
[ ACH-ALLC´93 ] - ACH-ALLC´93 Joint International Conference (16-19 June 1993), Conference Abstracts, Georgetown University, Washington, D.C., 1993. [ Back to reference: 157-59, 159-60, 160-61 ]
[ AFQ SD ] - J. André, R. Furuta, and V. Quint (eds.), Structured Documents, Cambridge, Cambridge University Press, 1989. [ Back to reference: 7-38, 75-105 ]
[ BD SM ] - F. Bocchi and P. Denley (eds.), Storia & Multimedia, (Proceedings of the Seventh International Congress of the Association for History and Computing: Bologna, 29 August-2 September 1992), Bologna, Grafis Edizioni, 1994. [ Back to reference: 642-46, ]
[ BL IC ] - L. I. Borodkin and W. Levermann (eds.), Istorja i Compjuter, St. Katharinen, Max-Planck-Institut für Geschichte i.K.b. Scripta Mercaturae Verlag, 1993. [ Back to reference: T SODP ]
[ B HS ] - D. Buzzetti, "'Historical software' e filologia," in Schede umanistiche, N.S., 3:2(1991), pp. 181-90. [ Back to reference: 187, 190 ]
[ B IP ] - D. Buzzetti, "Image Processing and the Study of Manuscript Textual Traditions," in Historical Methods, 28(1995), pp. 145-54 (reprinted, with changes, from FJ IPH, 45-63). [ Back to reference: 148(a), 148(b), 148(c), 149(a), 149(b), 150(a), 150(b), 150-51, 151(a), 151(b) ]
[ B MB ] - D. Buzzetti, "Masters and Books in 14th-century Bologna: An edition as a database," in BD SM, 642-46. [ Back to reference: cf, 643, 644(a), 644(b) ]
[ BT ICT ] - D. Buzzetti and A. Tabarroni, "Informatica e critica del testo: Il caso di una tradizione 'fluida'," in Schede umanistiche, N.S., 1:2(1991), pp. 185-93. [ Back to reference: cf, 190, 193 ]
[ FJ IPH ] - J. Fikfak and G. Jaritz (eds.), Image Processing in History: Towards open systems, St. Katharinen, Max-Planck-Institut für Geschichte i.K.b. Scripta Mercaturae Verlag, 1993. [ Back to reference: 45-63 ]
[ F CM ] - R. Furuta, "Concepts and Models for Sructured Documents," in AFQ SD, 7-38. [ Back to reference: 13 ]
[ G EDT ] - G. L. Greco, "The Electronic Diplomatic Transcription of Chrétien de Troyes´ 'Le Chevalier de la Charrette (Lancelot)': Its forms and uses", in ACH-ALLC´93, 159-60. [ Back to reference: 159a, 159b ]
[ ISO ODA ] - ISO, Office Document Architecture, Draft International Standard 8813, International Standard Organisation, 1986. [ Back to reference: cf ]
[ J IAS ] - G. Jaritz, Images, a Primer of Computer-supported Analysis with kleio IAS, St. Katharinen, Max-Planck-Institut für Geschichte i.K.b. Scripta Mercaturae Verlag, 1993. [ Back to reference: cf ]
[ J DR ] - V. Joloboff, "Document Representation: Concepts and standards," in AFQ SD, 75-105. [ Back to reference: n5 ]
[ K PvK ] - K. Kanzog, Prolegomena zu einer historish-kritish Ausgabe der Werke Heinrich von Kleist: Theorie und Praxis einer modernen Klassiker-Edition, München, Hanser, 1970. [ Back to reference: 19, 40-41 ]
[ K EP ] - H. Kraft, Editionsphilologie, Darmstadt, Wissenschaftliche Buchgesellshaft, 1990. [ Back to reference: 15, 110, 110-11a, 110-11b, 111, 150, 157 ]
[ M UT ] - A. Maierù, University Training in Medieval Europe, Leiden, Brill, 1994. [ Back to reference: 55-62 ]
[ O IU ] - T. Orlandi, Informatica umanistica, Roma, La Nuova Italia Scientifica, 1990. [ Back to reference: 142, 144 ]
[ P CD ] - T. Paff, "The 'Charrette' Database: Technical issues and experimental resolutions," in ACH-ALLC´93, 160-61. [ Back to reference: 161 ]
[ T IM ] - M. Thaller (ed.), Images and Manuscripts in Historical Computing, St. Katharinen, Max-Planck-Institut für Geschichte i.K.b. Scripta Mercaturae Verlag, 1992, pp. 41-72. [ Back to reference: 41-72 ]
[ T PM ] - M. Thaller, "The Processing of Manuscripts", in T IM, 41-72. [ Back to reference: cf, 52(a), 52(b), 54, 55-56, 56-57, 57ff ]
[ T BMV ] - M. Thaller, "Bild- und Manuskriptverarbeitung auf dem IBM RISC System/6000," in Offene Grenzen - offene Systeme: Dokumentation (IBM Hochschulkongress ´92: Dresden, 30. September-2.Oktober 1992), Bonn/München, IBM Deutschland GmbH, 1992. [ Back to reference: cf ]
[ T KDBS ] - M. Thaller, Kleio. A Database System, St. Katharinen, Max-Planck-Institut für Geschichte i.K.b. Scrpta Mercaturae Verlag, 1993. [ Back to reference: cf ]
[ T SODP ] - M. Thaller, "What is Source-oriented Data Processing? What is Historical Computer Science," in Historical Methods, forthcoming (translated from BL IC). [ Back to reference: cf ]
[ T SDIF ] - M. Thaller, "The Archive on Top of Your Desk: An Introduction to Self-Documenting Image Files," in Historical Methods, 28(1995), pp. 133-143. [ Back to reference: cf, 138-40 ]
[ U OFM ] - K. D. Uitti, "Old French Manuscripts, the Modern Book and the Electronic Image," in ACH-ALLC´93, 157-59. [ Back to reference: 157(a), 157(b), 157(c), 157(d), 157-58,(a) 157-58(b) ]
[ T OFM d ] - K. D. Uitti, "Old French Manuscripts, the Modern Book and the Electronic Image: the Princeton 'Charrette' Project" (draft), p. 10. [ Back to reference: 10, 15 ]
[ WD TK ] - M. Woollard and P. Denley, Source-oriented Data Processing for Historians: A tutorial for kleio, St. Katharinen, Max-Planck-Institut für Geschichte i.K.b. Scrpta Mercaturae Verlag, 1993. [ Back to reference: cf ]
This paper reproduces, with minor corrections, the text presented at the electronic session of the Electric Scriptorium conference, on 12 November 1995.
Further developments of the project described here are discussed in the following publications:
Copyright © 1995-1998
WWW adaptation: 31 July 1998
Last Updated: 9 October 1998
![]() Dino Buzzetti
Dino Buzzetti
![]() Andrea Tabarroni
Andrea Tabarroni